Локальные языковые модели (LLM)¶
Дисклеймер
Работа с LLM и их понимание требует некоторых базовых навыков, знаний математики и продвинутого пользования пека, а также железа для их запуска. Текст ниже рассчитан на обладающих этими качествами.
Поскольку описывается широкий перечень понятий, некоторые определения и принципы представлены кратко и упрощенно для лучшего понимания.
Базовые понятия¶
Термины¶
Ниже представлен краткий перечень терминов с упрощенным описанием.
- Веса/модель - сама нейросеть, численные значения параметров ее слоев и конфигурация. Может иметь вид единичного файла (в 99% случаев .gguf) или папки с множеством файлов.
- Токен - квант информации, слог, слово, группа символов, то как модель видит текст. Ближайшая аналогия - кодировки текста, только на один токен может проходится как группа символов, так и наоборот, несколько токенов на один символ. У каждой модели может использоваться своя таблица токенов, обеспечивающая наиболее эффективное их использование с учетом текста.
- Токенайзер - переводчик текста в токены и обратно. У разных моделей могут быть разные, от них зависит расход токенов на конкретный текст. Поскольку большая часть моделей рассчитаны на английский язык - текст на инглише (или в целом латиннице) потребляет наименьшее количество токенов (в среднем 1-2 на слово), а кириллица может потребовать вдвое больше на тот же объем символов. Эмодзи и специальные символы и вовсе потребуют нескольких токенов на один. Ознакомиться с примером или поиграться можно здесь.
- Контекст - история чата, тот объем текста что модель будет обрабатывать. Включает в себя также и системный промт, карточки персонажей и прочее прочее если речь идет о РП. Размер контекста у модели ограничен (у Llama2 базовое значение 4096 токенов), модель "помнит" и только то что у нее в контексте. Если ваши поцелуи с вайфу, упоминание важного события в рп, или обозначение какого-то термина в чате вышли за контекст - модель не будет о них помнить и не поймет, или интерпретирует согласно своим общим знанием. Проблема ограниченного контекста решается суммаризацией, лорбуками, векторными базами данных и другими приёмами. Или просто увеличением контекста.
- Квантование - эффективное lossy сжатие модели, аналогия - h264 для видео.
- Стриминг - выдача ответа в реальном времени, позволяет видеть и читать его сразу вместо ожидания завершения генерации ценой небольшого снижения общей скорости.
- Лаунчер - бек энд, программа которая производит расчеты и обеспечивает работу текстовой нейросети.
- text-generation-webui - программа, обеспечивающая организацию запуска популярных лаунчеров и удобный веб-интерфейс, объединяет в себе и фронт и бек. Наилучшее с точки зрения универсальности и возможностей решение, но так же сложное в установке и обслуживании.
- Убабуга - oobabooga автор text-generation-webui, его же именем часто этот интерфейс и называют
- Жора - Georgi Gerganov автор llama.cpp, наиболее популярного лаунчера для запуска LLM на различных девайсах (и других проектов)
- Таверна - SillyTavern, некогда форк TavernAI сейчас значительно развившийся и превосходящий оригинал. Рекомендуется для использования фронтом для РП, существуют и другие альтренативы.
- Кобольд - kobold_cpp, форк llamacpp объединяющий ее с интерфейсом аналогичным koboldai. Имеет ключевое преимущество в виде простоты установки на windows.
- Обниморда - https://huggingface.co
- Лупы - ситуация, когда модель "ломается" и начинает регулярно в каждом последующем ответе или в одном посте повторяется. Может заключаться в повторении стиля речи, шаблона поста, действий, одинаковых фраз, и вплоть до спама одной буквы.
- Алайнмент модели - смещение ее ответов в определенных условиях в сторону от нейтрального, добавление убеждений и т.п. В большинстве случаев - добавление "человеческих ценностей" чтобы сделать модель "безопасной".
- Соя - алайнмент в сторону "позитивного мышления". Может иметь диапазон от легкого, в котором модель просто предупредит об опасности или негативной оценке запроса, до значительного, в котором модель становится леворадикальным активистом, и напрочь отказывается генерировать любой текст, в котором негры/феминистки/... представляются в негативном свете, или просто жестокий или сексуализированный контент.
Работа LLM¶
Все что делает текстовая модель - выдает вероятности токенов, которые могли бы продолжить обработанный ею контекст. Последовательно повторяя этот процесс можно получать уже не единичные слоги, а полноценный текст. Есть разные подходы к обработке вероятностей токенов, важны два:
- Жадный энкодинг - берется просто токен с наибольшей вероятностью. Рабочий, но не самый эффективный с точки зрения качества текстов метод, также в нем невозможно получить разнообразные ответы на одинаковый контекст и нет управы на лупы.
- Семплирование - с учетом полученных вероятностей выбирается случайный токен из выдачи. Для обеспечения адекватности результатов, с распределениями вероятностей токенов сначала производится последовательность операций отдельных семплеров, каждый из которых производит их возмущения, или отсекает по определенному критерию. Beam search - подвид семплирования, который включает обработку не единичного токена каждый раз, и их цепочек, с последующим их сравнением. Почитать можно здесь и в гугле. Ввиду ресурсоемкости используется реже.
Семплеров существует множество, вот основные:
- top P - отсекает наименее вероятный токены, сохраняя наиболее вероятные, суммарная вероятность которых будет больше или равна заданному числу. Например, если у нас идут токены с вероятностями 0.5, 0.22, 0.12, 0.02, 0.01, 0.0001, ... и установлен topP 0.8 то далее пройдут первые 3 токена (0.5+0.22+0.12=0.84), а остальные отсечены. Если параметр равен единице то в выдачу попадут все токены.
- top K - оставляет только первые N (установленное значение параметра) токенов упорядоченных по вероятности, отсекая остальные. topK=10 - сохранит первые 10 наиболее вероятных токенов, отсекая остальные.
- min P - отсекает токены с вероятностью minP * (вероятность наиболее вероятного токена). Например, при параметре 0.05 при вероятности 1-го токена 30% отсечет все остальные с вероятностью ниже 1.5%.
- top A - отсекает токены с вероятностью topA*p_max^2 где p_max - вероятность наиболее вероятного токена.
- repetition penalty - при значениях больше 1 дает штраф (зависит от значения) к вероятности токенов, которые уже есть в рассматриваемом диапазоне контекста.
- temperature - при значениях меньше 1 снижает вероятность токенов с меньшей вероятностью (при этом, соответственно, повышая ее для наиболее вероятных делая результат при семплировании ближе к жадному энкодингу). При значении выше наоборот повышает ее, повышая разнообразие. При высоких значениях есть шанс на получение неаедкватной выдачи. Установка параметра в ноль превращает выборку в жадную.
Соответственно, обобщенно стандартный процесс семплирования можно представить как отсеивание маловероятных и повторяющихся токенов, и возмущение их вероятности в сторону повышения вероятности для менее вероятных, или наоборот увеличения разрыва между более и менее вероятными. После обработки семплерами проводится розыгрыш из оставшихся токенов с учетом их новых значений вероятности. Более подробно про семплеры почитать можно на обниморде 1 2 в вики кобольда или еще где-нибудь в гугле.
Сама работа модели включает себя 2 этапа:
- Сначала происходит обработка контекста (каждый его токен по очереди)
- Далее идет расчет и выдача распределения вероятностей следующего токена.
Производя выбор токена из полученного распределения и последовательно повторяя операцию можно генерировать текст. Обработанный контекст кэшируется чтобы не повторять операцию каждый раз, поэтому саму генерацию текста можно разделить на 2 фазы:
- обработка контекста
- генерация токенов.
Они требуют разных ресурсов что будет важно для производительности, о которой далее. Обработка контекста всегда происходит быстрее генерации, применение видеокарты позволяет ускорить ее на порядки, сделав операцию почти мгновенной. Также контекст кэшируется и между запросами, за счет чего в режиме чата обрабатывается только последние сообщения.
Размер контекста¶
Базовый контекст в LLama2 и основанных на ней моделей составляет 4к токенов, в более ранних llm было вообще 2к или менее, за редкими исключениями. Однако, есть способ его увеличения с помощью NTK Rope. За него отвечают параметры rope_freq_base или alpha в лаунчерах.
Можно получить 8к контекста в LLama2 и подобных
Без (заметной) потери производительности. Для этого достаточно выставить в параметрах контекст 8192, и alpha 2.65 или rope_freq_base 26900.
Величины alpha и rope_freq_base связаны формулой, которая может быть упрощена до
rope_freq_base=10000 * alpha(64/63)
Зависимость нужной альфы для разных контекстов LLAMA2 имеет следующий вид:
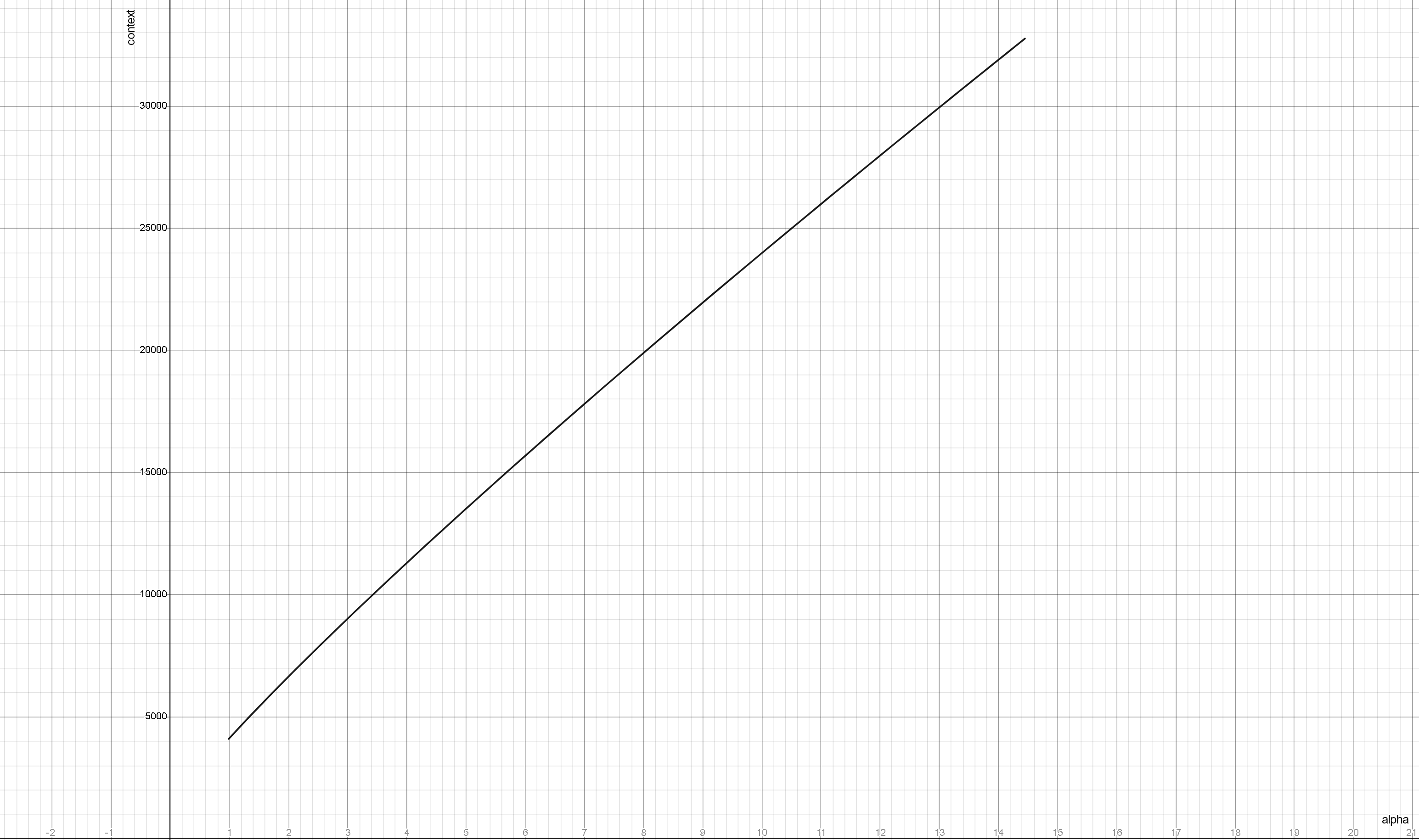
Сильное (более 2-3х раз) увеличение контекста относительно исходного для модели будет приводить к ухудшению качества ответов.
Некоторые модели изначально тренируются с использованием подобных параметров, что позволяет увеличивать контекст до огромных величин (32k-64k-100k-200k-...) без существенного импакта к качеству. Для корректной работы необходимы использовать соответствующие параметры ROPE при загрузке модели. При этом, при загрузке модели, не обязательно сразу задавать весь доступный объем, если не планируется его использование, поскольку на выделение контекста расходуется память.
Языки, поддержка русского и прочее¶
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Виды моделей¶
Моделей сейчас представлено множество, большая их часть на основе LLama2. В целом все можно разделить на следующие группы:
- Базовые - тренированы с нуля, универсальны, в зависимости от авторов могут или не иметь какого-либо байаса, или наоборот быть сильно смещенными. Наиболее "чистые" и свободные от криворуких улучшателей, однако, часто, имеют не лучший перфоманс в конкретных темах и ролплее. Для Llama1 были размером 7-13-33-65 миллиардов параметров, для Llama2 - 7-13-70, CodeLlama - 7-13-34, Llama3 - 8-70.
- Базовые -chat, -instruct и прочее - по сути файнтюны от разработчиков. Обычно имеют своей целью лучшее следование инструкциям, следование формату чата и общее выравнивание/безопасность. Всегда более соевые, нежели чем базовые версии.
- Файнтюны - дотренировка базовых моделей на определенных датасетах с целью расширения их знаний в какой-то области, придания стиля, добавлению каких-то фич типа явного ризонинга и цепи-мышлений в обычных ответах и т.д. В соответствующей теме (а иногда и почти во всех) работают лучше чем базовые. Из-за ошибок в синтетических датасетах или при специальных действиях могут приобрести дополнительную цензуру и аполоджайзы, или наоборот начать "вести себя слишком откровенно".
- (шизо)Мерджы/миксы - смеси файнтюнов с использованием различных техник. Обладают "особенностями" файнтюнов, но возведенными в абсолют. Редко или в узких областях могут оказаться лучше оригиналов, но в большинстве случаев страдают шизой и раздвоением мышления. При этом, могут показывать неплохие результаты в (эротическом) ролплее, для чего и используются. Ввиду простоты производства их количество огромно, качество разнится. По лучшей на данный момент - спрашивай в треде.
- Франкенштейны/химеры - когда мерджи зашли слишком далеко и их авторы решили пересадить последние N слоев одной модели поверх другой, предварительно отрезав ей меньшее количество. По желанию можно повторить и сделать конкретную нарезку. Не смотря на ужасное описание, некоторые из них действительно показывают перфоманс лучше чем у оригиналов, в ролплее разумеется. Детектятся по нестандартному размеру (сейчас 11 и 20б).
Также существуют техники как "апскейла" весов с дальнейшим файнтюном новых участков, так и дистилляции с их ужатием, в ходе которого из большей модели получается меньшая. Примером первого варианта может служить модель Solar-10.7b.
Размер модели и квантование¶
Запускать текстовые модели можно на видеокарте, на процессоре, а также одновременно на них деля на части. Первое очень быстро, второе (на простом железе) очень медленно, третье - компромисс посередине. Поэтому основным средством запуска остается видеоускоритель, база нейтросетей.
LLM имеют гораздо большее по сравнению с другими нейросетями число параметров, самые младшие из "умных" в настоящее время содержат ~7 миллиардов весов, что в половинной точности (fp16) занимает более 13 гигабайт. Соответственно, уже просто загрузка в память этой модели потребует почти 14гб, а помимо этого необходимо хранить данные текущих расчетов и обработанный контекст, так что даже теоретический ее запуск потребует минимум 16гб видеопамяти (в реальности почти 20).
Однако, в отличии от других нейросетей, текстовые модели подвержены гораздо меньшей деградации при снижении точности их весов. Разумеется речь идет не просто про использование 8-6-4-... битной точности вместо 16 бит, что можно встретить в старых имплементациях и приводило к ухудшению качества. Объем распределяется между разными частями модели давая большую точность участкам, которые наиболее значимы, и наоборот жертвуя теми, влияние которых наименьшее.
Таким образом, можно снизить точность модели до ~4бит, при этом сохранив ее основной функционал и качество. Такой процесс сжатия модели называют квантованием, в большинстве случаев для использования работают именно с квантованными моделями.
При квантовании может использоваться матрица важности (importance matrix, или Imatrix), то есть для разных весов может использоваться разная точность, что более эффективно распределяет доступную битность. Матрицы важности обычно тренируют на wikitext, что теоретически может негативно сказаться на способности модели генерировать прозу/текст на русском, но доказательств этому пока нет. Применимо к форматам GGUF и EXL2
По поводу квантованных моделей существует множество споров
касающихся вызванной этим деградацией, ухудшением качества, оптимальных алгоритмов и прочее прочее. Убедительных доказательств значительного ухудшения (если не брать совсем лоботомию до 2.5 бит), или наоборот полного сохранения перфоманса представлено не было.
Есть несколько известных фактов:
- Результаты модели, квантованной в 8 бит практически не имеют отличий от 16 битной
- Большие модели лучше переносят квантование даже в малые битности (~3 бита), тогда как на малых заметная деградация может проявиться уже на 4х или более (величины приводятся для примера).
- Квантованные (особенно в малую битность) модели малопригодны для обучения, есть алгоритмы типа QLora и подобные, но их результат будет хуже чем при работе с полноразмерными моделями.
- Сильное ужатие приведет к поломке и шизе, 3 бита можно считать нижней границей.
Форматы моделей¶
Все описанные форматы кроме GGUF распространяются папкой, в которой лежат как веса модели (файлы .bin или .safetensors), так и конфигурационные файлы json, токенизаторы и прочее. То есть для gguf достаточно скачать 1 файл (или все файлы в случае разделения большой модели на несколько), а для остальных форматов необходимо скачать весь каталог с моделью.
Из всей совокупности форматов нам интересны только GGUF и GPTQ/EXL2 кванты.
Веса huggingface, pytorch_model-xxx-of-yyy.bin¶
Оригинальные неквантованные веса, могут быть запущены с помощью Transformers, однако следует отметить что в ванильном представлении (без использования ядра exllama в text-generation-webui) он крайне неэффективно использует память. Из плюсов - поддержка всего и вся, легкость разработки новых фич, возможность запускать на процессоре и делить между разными видеокартами. Обычному нужен чтобы про него почитать и забыть. После прямой конверсии в safetensors оригинальные веса могут быть запущены с помощью Exllama 2 в fp16.
GGUF¶
Формат для Llamacpp, может быть запущен на процессоре, на видеокарте, на процессоре и видеокарте совместно, на маках с их общей памятью и ускорением и прочем.
Используется также во всяких форках llamacpp (kobold_cpp, ...). Если ты "счастливый" обладатель 8гб врам или менее, то это твой бро для запуска моделей побольше.
Размер кванта обознается как i1-qN_K_s, где i1- (или -imat-) — пометка для квантов с матрицей важности (если нету, то матрица важности не использовалась), N — битность (реальная не соответствует написанному, Q2 имеет более 3х бит), K — версия формата (читать ниже), буква после K это "подквант" (неофициальный термин, только что придумал). Из плюсов — все в одном файле, квантование в этот формат можно сделать на любом калькуляторе. Из минусов — редко кто квантует с матрицей важности, кванты хронически сломаны для новых моделей (например, для Llama 3 нашли как минимум 3 бага).
Версии формата:
- Legacy (
q4_0,q4_1и т.п.) Старые кванты, не рекомендуются (исключение - Q8_0, других квантов под 8 бит не делают). - K-quants (
q4_K_s,q5_K_Mи т.п.) Достаточно свежий формат, рекомендуется. Подкванты: S - поменьше размером но пониже точностью, M - побольше но поточнее, L - еще больше (почти не встречается). База это Q5_K_M. - I-quants (
IQ3_XXS,IQ4_XS) Самый свежий тип квантов. Обладает меньшим размером, но в 2-3 раза медленнее при выполнении на CPU (скорость на видеокарте не отличается, если верить документации). Имеет большее число градаций подкванта: XXS, XS, S, M, NL, в порядке возрастания точности и веса файла.
GPTQ¶
Один из первых форматов квантованной модели (при этом достаточно эффективный).
Может быть выполнен в 3, 4 и 8 бит, также содержит параметры group size а act order, определяющие внутреннюю структуру и размер. Самый простой - без act order с одной группой. Самый жирный - 32 группы с act order, на "4 битах" имеет эффективную битность ~4.65. Может быть запущен с помощью разных лаунчеров, наиболее интересен Exllama (2), который работает на видеокарте и обеспечивает максимальную скорость.
AWQ¶
Более новый формат для видеокарты.
По заявлениям, обещают большую эффективность квантования по сравниню с GPTQ, что 3 бита AWQ равно 4 битам GPTQ (подтверждений этому не замечено). Может быть запущен с помощью AutoAWQ в Text Generation WebUI. Формат относительно редкий и не рекомендуется к скачиванию.
EXL2¶
Новый формат для лаунчера Exllama2.
Похож на gptq, но позволяет делать квантование в произвольную битность с обязательным использованием матрицы важности. Из минусов - кантование требует времени и ресурсов, используемый про оценке датасет может влиять на качество кванта (по степени влияния и его наличии достоверных данных нет). Если в процессе допущена ошибка (например, использована оценка для другой модели) - результат может оказаться посредственным. Запускается через Exllama2. Работает только на видеокарте.
Лаунчеры¶
Из всей совокупности лаунчеров нам интересны только Exllama2 и Llamacpp.
Стоит отметить что у каждого из ланучеров реализован свой набор семплеров и функций
И они отличаются от дефолтных, представленных в трансформерсе.
Для обеспечения полного функционала в убабуге реализованы дополнительные обертки Exllama2/Llamacpp лаунчеров с приставкой HF (HuggingFace). Также эти версии позволят использовать CFG и негативный промт. Последний является наиболее мощным средством в расцензуривании модели и управлении ее поведением.
По скорости при прочих равных положение следующее:
- Exllama2 быстрее в ~1.2-2 раза чем Llamacpp (на амперах и новее, на более старых картах результат не однозначный), требует меньше памяти на ту же битность и тот же контекст.
- Llamacpp с полной выгрузкой слоев на видеокарту. Медленнее exllama и не так эффективно, но все еще очень быстро.
- Llamacpp с частичной выгрузкой слоев на гпу. Чем их меньше и чем слабее карточка тем медленнее. Можно использовать видеокарту (почти любую) для ускорения обработки контекста, будет не так больно.
- Llamacpp только на процессоре. Оно того не стоит, в случае потери кэша контекста только его обработка может занять несколько (десятков) минут, а после выхода на максимальный контекст в рп он будет пересчитываться каждый раз.
Потребление памяти и скорость зависит также и от контекста. В случае exllama2 (с работающим flash attention) расход на него заметно меньше, и обрабатывается он быстрее.
Список актуальных семейств¶
LLaMA¶
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2. Недавно вышедшая Llama 3 в размере 70B по рейтингам LMSYS Chatbot Arena обгоняет многие старые снапшоты GPT-4 и Claude 3 Sonnet, уступая только последним версиям GPT-4, Claude 3 Opus и Gemini 1.5 Pro.
Кроме LLaMA для анона доступны множество других семейств моделей:
Pygmalion¶
Заслуженный ветеран локального кума. Старые версии были основаны на древнейшем GPT-J, новые переехали со своим датасетом на LLaMA, но, по мнению некоторых анонов, в процессе потерялась Душа ©
MPT¶
Попытка повторить успех первой лламы от MosaicML, с более свободной лицензией. Может похвастаться нативным контекстом в 65к токенов в версии storywriter, но уступает по качеству. С выходом LLaMA 2 с более свободной лицензией стала не нужна.
Falcon¶
Семейство моделей размером в 1, 7, 40 и 180B в первой версии и 11B во второй от какого-то там института из арабских эмиратов. Примечательна версией на 180B, что является крупнейшей из современных открытых моделей. По качеству (по заявлениям разработчиков) несколько выше LLaMA 2 на 70B, но сложности с запуском и малый прирост (а точнее полный отсос у более новых сеток) делаю её не интересной. Есть мультимодальная версия с поддержкой картирок Falcon2-11B-vlm.
Mistral¶
Модель от Mistral AI размером в 7B, с полным повторением архитектуры LLaMA. Интересна тем, что для своего небольшого размера она не уступает более крупным моделям, соперничая с 13B (а иногда и с 70B), и является топом по соотношению размер/качество. Также, разработчики выложили модели с использованием MOE - Mixtral 8x7b и 8x22b, которые за счёт своей архитектуры могут давать отличные ответы с высокой скоростью. Тем не менее, идут споры по поводу ее производительности в чем-то сложнее ответов на простые запросы.
Miqu¶
Утечка из Mistral AI, предположительно Mistral-medium или large. Модель на архитектуре LLaMA с размером в 70B. К сожалению, доступны только квантованные версии, а методы разквантования весов ухудшают модель, так что будущего у неё нет. Но в оригинальных квантах хороша сама по себе. Качать только оригинальные кванты с https://huggingface.co/miqudev/miqu-1-70b
Qwen¶
Семейство моделей размером в 7B, 14B, 72B и даже 110B от наших китайских братьев. Отличается тем, что имеет мультимодальную версию с обработкой на входе не только текста, но и картинок. В принципе хорошо умеет в английский, но китайские корни всё же проявляется в чате в виде периодически высираемых иероглифов.
Yi¶
Семейство китайских моделей на 1,5, 6, 9 и 34B (с версии 1.5). Самый интересный размер тут 34B, так как способен занять разрыв между 8 и 70B у Llama 3.
Solar¶
Модель с промежуточным размером между 7б и 13б, файнтюны которой показывают хорошее рп с учетом своего размера, и могут полностью помещаться к 12гб видеопамяти при использовании квантов.
Command R¶
Command R и Command R+ это модели 35B и 104B соответственно, от CohereForAI. Обладают хорошей поддержкой мультиязычности, в том числе хорошей производительностью на русском. Родной контекст 128к, ориентирован на RAG, но имеет неплохую чистую производительность.
Aya 23¶
Модели размером в 8B и 35B от CohereForAI с упором на многоязычность, 23 официальных языка, включая русский.
Microsoft Phi¶
В третьем поколении насчитывает 3.8B и 14B параметров, и до 128к контекста. Так же есть версия Vision (то есть которая умеет в картинки) на 4.2B. Как говорит сама Microsoft, "Safety-first model design", то есть модель отличается запредельным, непробиваемым уровнем сои. В остальном для своих размеров хороша, подойдёт совсем нищебродам с калькулятором вместо ПК.
Grok¶
Модель от самого Илона Масковича размером аж в 314B. Нахуй оно такое нужно, не знает никто. Зато 8k контекста!
Gemma¶
Семейство моделей от Google размерами в 2 и 7B в первой версии и 9B и 27B во второй. Контекст 8k. Скоры 27B выглядят неплохо, но пока не подтянулись средства запуска.
Мультимодальные модели¶
Светлым будущим локальной генерации наверняка будут мультимодальные модели, это когда к основной LLM сбоку приделывают модуль распознавания изображений, что в теории должно позволять LLM понимать изображение, отвечать на вопросы по нему, а в будущем и манипулировать им. Но сейчас тема околозаглохла.
TODO: добавить инфу о мультимодалках
Ссылки на модели и гайды¶
https://huggingface.co/TheBloke Основной поставщик квантованных моделей под любой вкус до 1 февраля 2024 года
https://huggingface.co/LoneStriker, https://huggingface.co/mradermacher Новые поставщики квантов на замену почившему TheBloke
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
https://ayumi.m8geil.de/erp4_chatlogs/ Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard Сравнение моделей по (часто дутым) метрикам (почитать характерное обсуждение)
https://chat.lmsys.org/?leaderboard Сравнение моделей на "арене" реальными пользователями. Более честное, чем выше, но всё равно сравниваются зирошоты
https://huggingface.co/Virt-io/SillyTavern-Presets Пресеты для таверны для ролеплея
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
https://rentry.co/llm-models Актуальный список моделей от тредовичков
Факультатив¶
https://rentry.co/Jarted Почитать, как трансгендеры пидарасы пытаются пиздить код белых господинов, но обсираются и получают заслуженную порцию мочи