Диффузионные модели¶
В этой статье рассматривается общая информация об открытых диффузионных моделях, предназначенных для генерации изображений и видео.
Информацию по конкретным семействам моделей и их производным вы можете найти по ссылкам ниже, либо использовав навигационную панель слева.
Хронология развития¶
Ниже представлена хронология выпуска открытых диффузионных моделей и ключевых технологий, которые повлияли на развитие генерации изображений и видео.
FAQ¶
Какую модель выбрать для генерации изображений?
На момент сентября 2025 самыми популярными и актуальными остаются модели на основе SDXL.
Для SFW генераций без сложного позинга вам так же может быть интересен FLUX, Qwen-Image и WAN 2.2.
Какую модель выбрать для генерации видео?
WAN 2.2
Виды моделей¶
Базовые модели¶
Базовая модель — обученная с нуля модель.
Создание базовых моделей требует колоссальных вычислительных ресурсов. В связи с этим, практически не существует базовых моделей, выпущенных энтузиастами. Пока это, по большей части, удел крупных компаний.
Совместимость
LoRA-модели и ControlNet-модели от одних базовых моделей не подходят к другим базовым моделям.
Разные базовые модели потребляют разное количество VRAM.
Таблица актуальна для NVidia:
| Базовая модель | Минимальный объём VRAM | Рекомендуемый объём VRAM |
|---|---|---|
| Stable Diffusion 1 | 4 GB VRAM | 8 GB VRAM |
| Stable Diffusion XL | 8 GB VRAM | 12 GB VRAM |
| FLUX | 12 GB VRAM | 24 GB VRAM |
Finetune¶
Finetune — дообученная версия базовой модели.
Обучение файньюнов требует умеренных вычислительных ресурсов (в сравнении с созданием базовых моделей), в связи с чем существует большое количество моделей данного вида, созданных различными группами энтузиастов или одиночками.
Примеры файнтьюнов: PonyDiffusion V6 XL, NovelAI V1
Merge¶
Merge — результат процедуры слияния нескольких моделей, или модели с LoRA-моделями.
Создание мёрджей не требует процедуры обучения и может быть выполнено в короткие сроки на потребительском ПК, в связи с чем мёрджи являются самым многочисленным видом моделей. Мёрджи создаются при помощи таких утилит как sd-webui-supermerger.
Во многих случаях используют окончание *****Mix в названии.
Примеры мёрджей: AutismMix, MeinaMix
Inpaint¶
Inpaint-модель — модель с дополнительными слоями, натрененированная специально для процесса инпеинта.
Данные модели не подвержены проблеме наличия швов и неконсистентности во время процедур inpaint/outpaint.
Примеры inpaint-моделей: foocus-inpaint
Вариации моделей¶
Формат файла: ckpt vs safetensors¶
Рекомендация
При наличии выбора используй safetensors
.ckpt - это старый формат моделей. Кроме весов, он содержит исполняемый код на python, который может быть вредоносным. Сейчас встречается редко.
.safetensors это более новый формат - он не хранит ничего, кроме весов модели.
Точность: FP16 vs FP32¶
Рекомендация
При наличии выбора используй FP16
Про экспоненциальную форму записи чисел с плавающей запятой
Экспоненциальная форма записи — это представление вещественных чисел в виде двух составляющих:
- Порядок (англ: exponent) — степень числа
- Мантисса (англ: mantissa, significand или fractional part) — значащие цифры этого числа
Данная форма записи удобна для представления очень больших и очень малых чисел, а также для унификации их написания.

Примеры:
| Обычная запись | Экспоненциальная форма |
|---|---|
| 42 | +4.2e1 |
| 149597000 | +1.49597e8 |
| 0.00000001 | +1e-8 |
| -0.00000123 | -1.23e-6 |
FP16 и FP32 — это форматы хранения чисел с плавающей запятой.
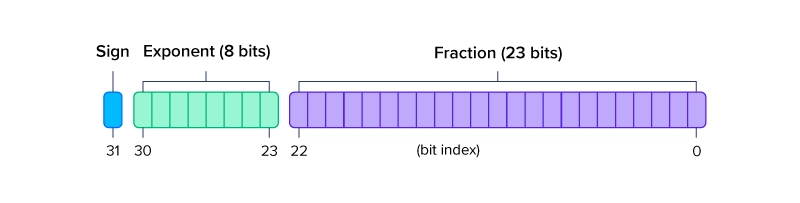
Формат FP32 использует 32 бита для хранения отдельного числа:
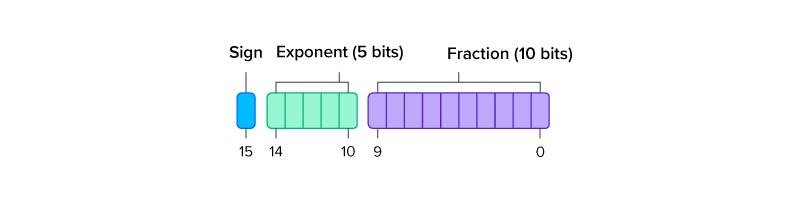
Формат FP16, так же называемый половинной точностью (half-precision), использует 16 бит для хранения отдельного числа:
По умолчанию, модели формата FP32 так же загружаются с половинной точностью, поэтому профита от большего размера не будет.
Современные модели, такие как FLUX, используют точность BF16 по умолчанию. Как и в случае FP16, используется 16 бит на одно число, но соотношение используемого количества бит для мантиссы и порядка отличается.

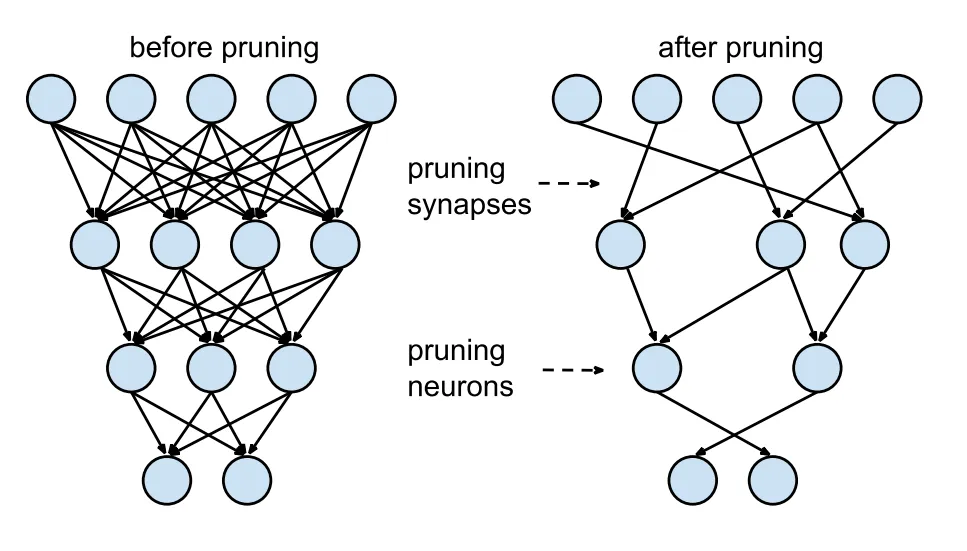
Избыточные связи: full vs pruned¶
Рекомендация
При наличии выбора используй pruned
В pruned версиях удалены избыточные связи внутри нейронки, благодаря чему она занимает меньше места. В теории, это слегка ухудшает качество модели, на практике разница малозаметна.
Составляющие части модели¶
Чекпоинт (checkpoint) — файл, хранящий в себе веса какой-либо модели. В случае картинко-генеративных нейростетей, один чекпоинт может включать в себя сразу несколько нейросетей, необходимых для генерации, а именно: U-Net, Text Encoder и VAE.
U-Net¶
U-Net — это архитектура сверточой нейронной сети, которая была разработанна для сегментации изображений ещё в далёком 2015 году. В случае картинко-генеративных нейросетей - это та часть модели, которая отвечает за пошаговое преобразование шума в изображение.
Text Encoder¶
Текстовый энкодер (text encoder) — нейросеть, которая извлекает смысл из текстового промпта и преобразует его в числовой вектор. Схожие по смыслу тексты имеют схожие векторы.
Примеры текстовых энкодеров: CLIP, T5.
VAE¶
VAE (Variational AutoEncoder) — архитектура нейросетей для эффективного сжатия и распаковки данных. В случае картинко-генеративных нейросетей, VAE — это нейронная сеть, которая преобразует RGB-изображение в латентное пространство и обратно.
Подробнее про VAE и латентное пространство смотри здесь.