Промпты¶
Промпт (prompt) - текстовое описание того, что вы хотите видеть на изображении.
Негативный промпт (negative prompt) - текстовое описание того, что вы не хотите видеть на изображении.
Текстовый энкодер (text encoder) - нейросеть, которая извлекает смысл из промпта и преобразует его в числовой вектор. Схожие по смыслу тексты имеют схожие векторы. Частные случаи текстовых энкодеров: CLIP-L, T5.
Позитивный и негативный промпты (cond и uncond) являются двумя разными одновременно влияющими на генерацию изображения кондишионами. С дев и шнель версиями флюкса, например, был дистиллирован uncond в угоду скорости, вернуть его можно только через костыли. Ожидаемо, генерируя с двумя кондишионами одновременно, скорость так же будет проседать в два раза, в автоматикоподобных гуях есть параметр для небольшого ускорения этого дела.
{kind=link}
Где брать теги¶
- https://danbooru.donmai.us/wiki_pages/tag_groups - список тегов с danbooru
- https://civitai.com/tag/wildcards - готовые наборы wildcards
- https://rentry.co/NAIwildcards - старый блокнот со списком тегов с бур по категориям
- https://e621.net/wiki_pages/1671 - фурри-теги
- https://huggingface.co/spaces/SmilingWolf/wd-tagger - автотаггер изображений, но output можно использовать как промпт в буру-формате
Гайды по составлению промптов¶
- https://stable-diffusion-art.com/prompt-guide
- https://civitai.com/articles/983/insights-for-intermediates-how-to-craft-the-images-you-want-with-a1111
Диалекты¶
Не забывай смотреть на рекомендации к составлению промптов для своей модели
Существует три основных способа, как можно описывать то, что вы хотите видеть на изображении.
Натуртекст¶
Опишите, что вы хотите видеть на картинке, в виде одного или нескольких предложений на английском языке, всё просто.
Натуртекст хорошо поддерживается базовыми моделями без явной специализации в генерации аниме, такими как SDXL или FLUX.
Буру (аниме) теги¶
Опишите, что вы хотите видеть на изображении, в виде перечисления тегов с анимешных бур, таких как https://danbooru.donmai.us
Любая модель, специализирующаяся на генерации аниме, как правило, поддерживает буру-теги.
Аниме модели легче всего юзать используя эти расширения для однокнопочного копирования тегов с бур, данбуру/аибуру, или гельбуру/другие движки.
Фурри теги¶
Похож на буру-теги, но используется система фурри-тегов с небезызвестного в узких кругах ресурса: https://e621.net
Некоторые из концептов описываются только в системе фурри-тегов, не имея аналогов в системе буру-тегов.
Фурри-теги хорошо поддерживаются только моделями, специализирующимися на генерации фуррей. Впрочем, есть и исключения, смотри EasyFluff + HLL.
Синтаксис промптов¶
Сила тега (Attention/emphasis)¶
Использование () повышает приоритет и значимость тега, а [] уменьшает. Нейронка может воспринять такое усиление тега даже слишком буквально (смотри пик ниже). Скобочки можно вкладывать друг-в-друга. Но гораздо удобнее выделять нужные теги и менять их вес при помощи ctrl+ вверх/вниз чтобы выставлять числа.
Чрезмерное влияние () на примере

(тег)- увеличивает силу тега в 1.1 раз((тег))- увеличивает силу тега в 1.21 раз (= 1.1 * 1.1)[тег]- уменьшает силу тега в 1.1 раз(тег:1.5)- увеличивает силу тега в 1.5 раза(тег:0.25)- уменьшает силу тега в 4 раза (= 1 / 0.25)\(тег\)- экранирование скобок при помощи обратного слеша необходимо если скобки должны являться частью тега, например, при указании имени персонажа с указанием тайтла, в соответствии с его тегом на бурах. Делай так:rem \(re:zero\), не такrem (re:zero)
LoRA¶
Используйте синтаксис <lora:имя_файла:сила> или <lora:имя_файла> для подключения лоры напрямую в промпте, где имя_файла это имя файла с лорой без указания расширения, а сила это число (в большинстве случаев в диапазоне от 0 до 1, но возможны как отрицательные значения, так и значения, превышающие единицу) описывающее, как сильно лора должна влиять на итоговый результат. Лоры нельзя использовать в качестве негативного промпта, но можно использовать с отрицательным весом в качестве позитивного промпта. В случае, если вы не указали силу лоры, она будет равна 1.
Вызов лоры в автоматикоподобных гуях так же имеет полный синтаксис <lora:lora_name:te=:unet=:dyn=>. Который можно использовать в определённых ситуациях, когда хочется снизить например только вес энкодера в лоре. te= отвечает за вес энкодера и по дефолту идёт первым, если указать просто цифры, unet= отвечает за юнет, а dyn= за динамический ранг dylora, этот ключ не влияет на другие типы лор. Позиции можно свободно переназначить, например <lora:lora_name:unet=1:te=0:dyn=16>.
LyCORIS¶
Для подключения ликорисов (LoCon, LoHa, LoKr, DyLoRA) необходимо использовать аналогичный лорам синтаксис <lora:имя_файла:сила> или <lora:имя_файла>. Все особенности использования лор, описанные пунктом выше, являются применимыми и для ликорисов.
Кейворд <lora> тоже не единственный и имеется ещё старый <lyco> унаследованный из старых либ, до того как ликорисы стали полноценной частью гуя, он должен выдавать аналогичную картинку, если лора была натренена с дополнительными частями из ликориса.
Embeddings¶
Для применения эмбеддингов необходимо указать имя файла эмбеддинга без расширения в промпте таким же образом, как указываешь обычный тег (для использования эмбеддинга "bad-hands-5.pt" в промпте укажи bad-hands-5). Так же для эмбеддингов можно настраивать веса при необходимости, по аналогии с обычными тегами, например (bad-hands-5:0.8).
Если всё сделал правильно, то информация об использованном эмбеддинге будет отображаться рядом с инфой о генерации.

BREAK¶
Использование ключевого слова BREAK (обязательно в верхнем регистре) заполняет текущий чанк пустыми символами. Если вы начнёте писать текст после слова BREAK, то это приведет к созданию нового чанка.
BREAK связан с концепцией «бесконечных» промптов из А1111 – эдакий костыль, который позволяет скармливать моделям простыни с текстом при ограничении длины «контекста» текстового энкодера в 75 токенов.
Почему 75 (на самом деле 77)? Потому что OpenAI так натренировали свой CLIP, потом кто-то натренировал OpenCLIP с теми же характеристиками, и StabilityAI засунули их в свои модели как было. В теории, можно натренировать CLIP на б́ольшую длину контекста, просто никто этим не занимался.
Что же делает BREAK (так, как это расписывает вики A1111)
При вводе стандартных 75 токенов, которые обычно принимает Stable Diffusion, размер длины промпта увеличивается с 75 до 150. При дальнейшем вводе текста размер промпта увеличивается соответствующим образом. Для этого промпт разбивается на фрагменты (чанки) по 75 токенов, каждый из них обрабатывается независимо с помощью CLIP, а затем результат объединяется перед подачей в следующий компонент SD - Unet.
Например, промпт из 120 токенов будет разделен на два фрагмента: 75 токенов и 45 токенов. Оба фрагмента «дополняются» до длины в 75 токенов, то есть второй фрагмент получается 45 токенов + 30 «пробелов». Пропустив эти два фрагмента через CLIP, на выходе получается два тензора с формой (1, 77, 768). В результате их объединения получается тензор (1, 154, 768), который затем без проблем передается в Unet.
BREAK предоставляет возможность разделить промпт так, чтобы какая-то его часть не оказалась на «стыке» при обработке CLIP’ом (что-то вроде «казнить нельзя помиловать»). Сам BREAK – это метатег из A1111, соответственно гарантированно работает он только в нём или его форках (Forge/ReForge), для Comfy вроде как нужны специальные ноды.
SD3, PixArt , Auraflow, Hunyuan и Flux используют систему на базе LLM (Т5) поверх CLIP, поэтому для них BREAK не существует в принципе.
Имеет ли смысл вообще использовать BREAK? Может быть только для SD1.5, так как он туповат. Для SDXL и прочих производных (Pony, NAI, Illustrious) эффект обычно минимальный.
Prompt editing¶
Extra Networks
Prompt editing не позволяет динамически переключать дополнительные сети, такие как лоры/ликорисы, а, так же, не позволяет переключать их веса. Такой функционал может быть добавлен при помощи плагина stable-diffusion-webui-composable-lora.
Данный синтаксис позволяет динамически менять промпт в промежутках между отдельными шагами сэмплера (Sampling Steps). В качестве аргумента when во всех примерах указывается либо целочисленное число шагов, после которого происходит переключение запросов, либо указывается число процентов (в виде дробного числа диапазоном от 0 до 1), которое описывает, через сколько процентов шагов произойдёт переключение запроса.
[from:to:when]¶
Данный синтаксис добавляет в запрос строку from, которая будет заменена на строку to через when шагов.
Пример [from:to:when]
Для примера, сгенерируем картинку с Sampling Steps = 30, содержащую следующий запрос:
[__backgrounds/autumn__:__backgrounds/destroyed-church__:VAR]
В зависимости от значения VAR, мы получим координально-отличающиеся изображения:

Определения использованных вайлдкардов в примере:
__backgrounds/autumn__=autumn, falling yellow leaves, park with trees__backgrounds/destroyed-church__=girl explores ruins of church, broken stained glass, deserted spaces
В данном случае мы комбинируем два разных запроса на фоны - изначально мы будем запрашивать "осенний пейзаж", а затем переключим запрос на "девочку, которая находится в разрушенной церкви".
- 0 - мы полность игнорируем запрос на осенний пейзаж и начинаем запрашивать церковь с первого кадра
- 5 - начинаем запрашивать церковь с пятого шага; как видно, следы осеннего пейзажа полностью пропали
- 10 - запрашиваем церковь начиная с десятого кадра; наиболее удачный вариант - на изображении присутствуют составляющие обоих запросов
- 15-30 - картинка с осенним пейзажом была сформирована, и нейронка не смогла перестроить картинку под церковь
Данная конструкция может быть использована для того, чтобы задать общую композицию через запрос from и отдельно описать детали через запрос to.
[to:when]¶
Добавляет to в запрос через when шагов.
[from::when]¶
Удаляет from из запроса через when шагов.
[first|second]¶
Чередует между собой first и second на каждом шаге.
Так же возможно использование более чем двух опций за раз, по типу [first|second|third|fourth]. Для это случая порядок запросов будет first -> second -> third -> fourth -> first и так по кругу.
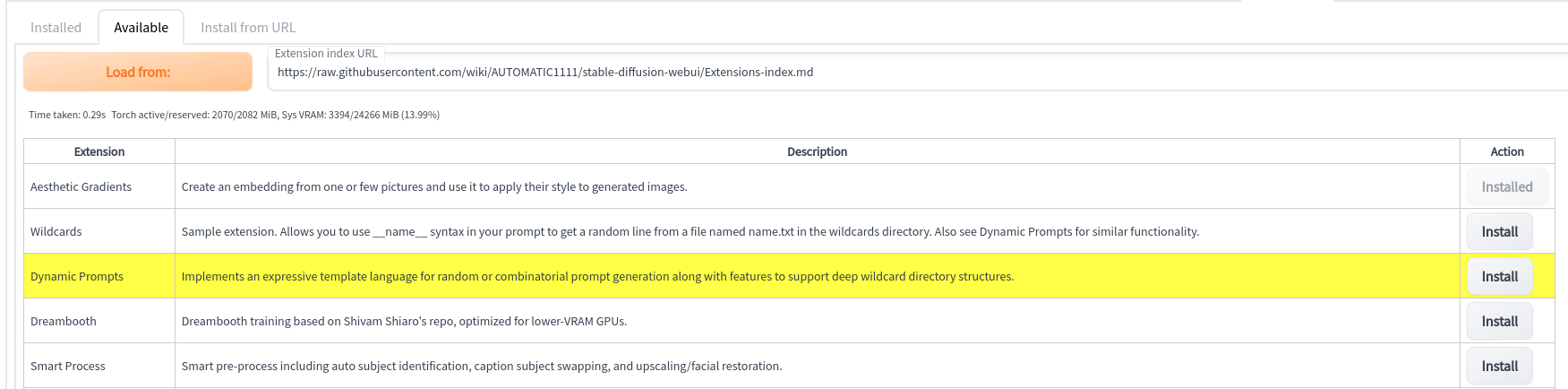
Dynamic Prompts¶
Требуется плагин
Синтаксис для динамических промптов не поставляется в AUTOMATIC1111 по умолчанию, для их использования необходимо установить плагин SD Dynamic Prompts, который проще всего поставить через панель расширений, встроенную в AUTOMATIC1111.
{kind=link}
Динамические промпты используют генератор псевдослучайных чисел, где функция выбора варианта зависит исключительно от текущего сида. Иными словами, при фиксации сида, вы может изменять модель, разрешение и т.п., и выбранный набор вариантов из динамических промптов останется тем же самым.
Более подробное описание синтаксиса Dynamic Prompts можно найти в официальной документации. Данный документ покрывает только наиболее востребованную часть синтаксиса.
Inline¶
{option1 | option2 | option3}¶
С равной долей вероятности будет выбран вариант 1, 2 или 3.
{5::summer | 1::autumn | 3::winter | 1::spring}¶
Задание распределения вероятностей - вариант с наибольшим числом в префиксе будет выпадать чаще. Если не указать одно из чисел, это будет интерпретировано как указание единицы в качестве веса.
{2$$Biba | Boba | Ilon Mask}¶
Выбор двух и более опций из нескольких вариантов, которые будут разделены запятой. Данный пример может вернуть один из следующих промптов (порядок элементов может быть произвольным):
Biba, BobaBiba, Ilon MaskBoba, Ilon Mask
{2$$ and $$Biba | Boba | Ilon Mask}¶
Аналогично варианту выше, но между двойными символами $ мы указываем свою строку для разделения. Данный пример может вернуть один из следующих промптов (порядок элементов может быть произвольным):
Biba and BobaBiba and Ilon MaskBoba and Ilon Mask
Wildcards¶
Описанные в текстовых файлах кусочки промптов (wildcards) могут использоваться для рандомизации запроса. Каждая новая строка считается отдельным вариантом из которых происходит выбор.
Пример использования вайлдкарда для рандомизации
pose.txt:
sitting
standing
lying
leaning forward
Вызов __pose__ в запросе вернёт одну случайную позу из списка.
Так же вайлдкарды могут использоваться как синонимы к длинным кускам промптам.
Пример использования вайлдкарда для создания синонимов
destroyed-church.txt
girl explores ruins of church, broken stained glass, deserted spaces, detailed background
Вызов __destroyed-church__ вернёт всю строку целиком.
Поскольку вайлдкарды поддерживают вызов лор/ликорисов, то вы можете описать в них лоры с соответствующими им тегами, чтобы не пришлось каждый раз их вспоминать.
__pose__¶
Используется для получения случайной строки из файла. Список файлов с вайлдардами по умолчанию хранится в директории /extensions/sd-dynamic-prompts/wildcards.
Пример __pose__
pose.txt:
sitting
standing
lying
leaning forward
Вызов __pose__ в запросе вернёт одну случайную строку из списка.
__places/*__¶
Используется для получения случайного файла со строками.
Пример __places/*__
wildcards
├seasons
└places
├indoors.txt
├outdoors.txt
└special
├abstract.txt
└space.txt
indoors.txt, либо outdoors.txt. Вложенные директории не проверяются.
__characters/**/*__¶
Аналогично варианту выше, но дополнительно проверяет вложенные директории.
Пример __characters/**/*__
wildcards
├seasons
└characters
├male
└female
├evangelion
└konosuba
├aqua.txt
├darkness.txt
└megumin.txt
В данном случае может быть выбран любой вариант, находящийся напрямую в директории characters, либо во вложенной директории.